Makine Öğrenmesi
Makine Öğrenmesi ile Web Sitesi Sınıflandırma
Bir web sitesini sınıflandırma ihtiyacının temeli, ticari faaliyetlere, gizlilik ve güvenlik kaygısına dayanmaktadır. Kategorisi belirli olan bir web sitesine reklam konumlandırmak veya belirli bir kategoriye ilgi duyan kullanıcının karşısına ilgili kategoriden reklamlar çıkarmak ticari anlamda büyük fayda sağlamaktadır. Kullanıcı açısından ise erişim sağlanmaması gereken kategoriler belirlenerek güvenli bir ağ oluşturulmasına katkı sağlanabilir.

13.06.2024

Yapılan web sitesi sınıflandırma çalışmaları incelendiğinde iki farklı yaklaşım görülmektedir: yalnızca alan adı bilgisi ile sınıflandırma, web sitesi içerik bilgisi ile sınıflandırma.
Her iki yaklaşımın da artıları ve eksileri bulunmaktadır. Alan adı her zaman web sitesi kategorisi ile ilişkili olmayabilir, web sitesi içerikleri çok fazla kelime içereceğinden hem eğitim aşamasında hem de test aşamasında fazla süre gerektirir. Bu çalışmada söz konusu olumsuzluklar dikkate alındı ve web sitelerinin meta verileri (başlık, tanım) kullanılarak sınıflandırma yapıldı.
Makine öğrenmesi modelinin oluşturulma adımları aşağıda görülmektedir:

Veri Seti: Çalışmada web sitesi sınıflandırma çalışmalarında sıklıkla kullanılan, web sitelerinin meta verilerini (başlık ve tanım) içeren DMOZ veri seti kullanıldı. Bu veri seti 1195850 satır, 4 sütundan oluşmaktadır. Ayrıca toplam 13 farklı kategoriden web sitesi içerir. Veri setinin ilk 5 satırı aşağıda görülebilir.
Veri Ön İşleme: Bu adımda ilk olarak başlık ve tanım kolonları birleştirilerek veri seti tek bir bilgi ve kategori kolonlarından oluşur hale getirildi. Sonrasında ise sırasıyla aşağıdaki adımlar uygulandı:
- Veri setinde “null” değer olup olmadığı kontrol edildi ve bulunan “null” değer içeren bir satır silindi.
- Mükerrer satır olup olmadığı kontrol edildi ve bulunan 9149 adet mükerrer satır temizlendi.
- İngilizce olan etkisiz kelimeler satırlardan arındırıldı.
- Büyük harfler küçük harflere çevrildi.
- Bir “regex” yazılarak kelimeler içerisinden noktalama işaretleri, rakamlar, fazla boşluklar kaldırıldı.
- Veri seti, dörtte biri test, kalanı eğitim kümesi olmak üzere iki parçaya ayırıldı.
Veri setinin veri ön işleme adımları uygulandıktan sonraki son hali aşağıda görülebilir.

Öznitelik Çıkarımı: Kelimeler tek başlarına makine öğrenmesi algoritmaları için bir anlam ifade etmez. Anlamlı hale getirilmesi için vektör temsilleri oluşturuldu. Bu işlemler için CountVectorizer ve TfidfTransformer kullanıldı. Scikit-learn kütüphanesinde bulunan CountVectorizer, metin verilerini kelime sayım matrisine dönüştürmek için kullanılır. Her belgedeki kelime sayısını hesaplar ve bu sayımları kullanarak bir belge-terim matrisi oluşturur. Bu matrisin her satırı bir belgeyi, her sütunu ise belirli bir kelimeyi temsil eder. Matrisin hücrelerinde ise ilgili kelimenin o belgede kaç kez geçtiği yer alır. TfidfTransformer ise bir terimin tüm belgeler arasında ne kadar yaygın veya nadir olduğunu ölçer. Çalışmada bir “pipeline” oluşturulup kelimeler sırasıyla CountVectorizer ve TfidfTransformer işlemlerine tabi tutularak kelime vektörlerine dönüştürüldü ve artık makine öğrenmesi algoritmaları için anlamlı hale gelen veri seti ilgili algoritmaya iletildi.
Model Seçimi: Metin sınıflandırma çalışmaları incelendiğinde çok farklı algoritmaların kullanıldığı görülmektedir. Bunlardan en çok tercih edilenleri Multinominal NB, SVM, CNN, LSTM algoritmaları olmuştur. Bu çalışmada da Naive Bayes algoritmasının bir varyasyonu olan ve özellikle ayrık verilerle çalışmak için tasarlanan Multinominal NB algoritması tercih edildi. Bu algoritma, metin sınıflandırma gibi kelime sayımlarının veya frekanslarının önemli olduğu görevlerde yaygın olarak kullanılmaktadır. Ayrıca model kurgulanırken modelin hiperparametlerini optimize etmek için RandomizedSearchCV yöntemi kullanılmıştır. RandomizedSearchCV, belirli bir hiperparametre aralığında rastgele olarak hiperparametre kombinasyonlarını seçip değerlendiren bir arama stratejisidir. Burada da hem öz nitelik çıkarımı aşamasında hem de model eğitimi aşamasında doğru parametrelerin seçilmesi için kullanılmıştır.
Sonuç Değerlendirme: Dengesiz bir veri seti ile çalıştığımız için “accuracy” metriği yanıltıcı sonuçlar üretebilir. Sonuçları değerlendirmek için metriği “precision”, “recall” ve “f1-score” değerlendirme metrikleri kullanıldı. Çoklu sınıflandırma işlemi yaptığımız için tek bir rakam ile değerlendirme yapmak mümkün olmamaktadır bu sebeple her bir sınıf için ayrı ayrı hesaplamalar yapıldı ve ortalama değerler de hesaplandı. Aşağıda her bir kategori için tüm değerlendirme metrikleri ve ortalama değerler görülebilir.
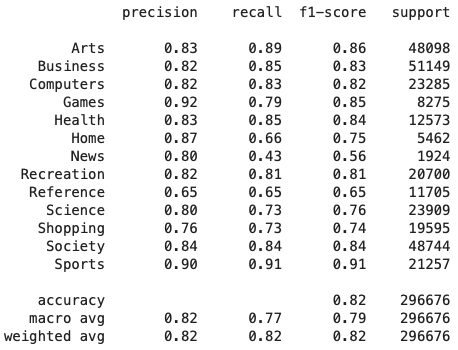
Bu çalışmada web sitelerinin meta verileri kullanılarak makine öğrenmesi ile bir sınıflandırma modeli tasarlandı ve elde edilen sonuçlar paylaşıldı. Bazı kategorilerin yüksek değerler bazılarının ise daha düşük değerler ürettiği görülmektedir. Veri setinin dengesiz olması burada temel etkendir. Dengesiz veri setlerinin sonuçlarını iyileştirmek için uygulanabilecek bazı teknikler mevcuttur. Bunlar uygulanarak ve veri ön işleme adımlarında ek iyileştirmeler yapılarak sonuçlar iyileştirilebilir.,
Uygulanan tüm adımların incelenebileceği Kaggle linki:
https://www.kaggle.com/code/berkayzam/web-categorization-project
Kaleminize sağlık.