Veri Setine aşağıdaki linkten ulaşılabilir: https://archive.ics.uci.edu/ml/datasets/Madelon
| In [71]: |
"""
Elimizdeki tüm veri kümeleri birer değişkene atanıyor.
Verisetlerinde kolon isimleri yer almadığı için ardışık rakamlar tanımlandı.
"""
import pandas as pd
test_data = pd.read_fwf("madelon_test.data", header=None)
train_data = pd.read_fwf("madelon_train.data", header=None)
train_labels = pd.read_fwf("madelon_train.labels", header=None)
valid_data = pd.read_fwf("madelon_valid.data", header=None)
valid_labels = pd.read_fwf("madelon_valid.labels", header=None)
label = valid_labels[0]
#Veri kümesinden 5 örnek veri şu şekildedir;
train_data.head()
|
| Out [71]: |
| |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
... |
490 |
491 |
492 |
493 |
494 |
495 |
496 |
497 |
498 |
499 |
| 0 |
485 |
477 |
537 |
479 |
452 |
471 |
491 |
476 |
475 |
473 |
... |
477 |
481 |
477 |
485 |
511 |
485 |
481 |
479 |
475 |
496 |
| 1 |
483 |
458 |
460 |
487 |
587 |
475 |
526 |
479 |
485 |
469 |
... |
463 |
478 |
487 |
338 |
513 |
486 |
483 |
492 |
510 |
517 |
| 2 |
487 |
542 |
499 |
468 |
448 |
471 |
442 |
478 |
480 |
477 |
... |
487 |
481 |
492 |
650 |
506 |
501 |
480 |
489 |
499 |
498 |
| 3 |
480 |
491 |
510 |
485 |
495 |
472 |
417 |
474 |
502 |
476 |
... |
491 |
480 |
474 |
572 |
454 |
469 |
475 |
482 |
494 |
461 |
| 4 |
484 |
502 |
528 |
489 |
466 |
481 |
402 |
478 |
487 |
468 |
... |
488 |
479 |
452 |
435 |
486 |
508 |
481 |
504 |
495 |
511 |
5 rows × 500 columns
|
| In [72]: |
test_data.info(), print(42*"-") , train_data.info()
|
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1800 entries, 0 to 1799
Columns: 500 entries, 0 to 499
dtypes: int64(500)
memory usage: 6.9 MB
-----------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2000 entries, 0 to 1999
Columns: 500 entries, 0 to 499
dtypes: int64(106), object(394)
memory usage: 7.6+ MB
| Out [72]: |
(None, None, None)
|
| In [73]: |
#Burada sınıf sayısı ve isimleri, her sınıfa düşen örnek sayısı gibi bilgiler görülmektedir.
train_labels.value_counts()
|
| Out [73]: |
| 1 |
1000 |
| -1 |
1000 |
| dtype: |
int64 |
|
| In [74]: |
#Veri kümesindeki her bir özniteliğe ait toplam eksik veri sayıları:
train_data.isnull().sum()
|
| Out [74]: |
| 0 |
0 |
| 1 |
0 |
| 2 |
0 |
| 3 |
0 |
| 4 |
0 |
| |
.. |
| 495 |
0 |
| 496 |
0 |
| 497 |
0 |
| 498 |
0 |
| 499 |
0 |
Length: 500, dtype: int64
Veri Setiyle ilgili ihtiyaç duyacağımız tüm verileri topladık. Bundan sonraki adımlarda veri önişleme yapacağız ve veri setini en iyi verimi alacağımız modele uygun hale getireceğiz.
|
| In [75]: |
#Veri kümesi içerisinde integer a dönüştürülemeyen değerlerin olduğu satırlar belirlenir.
X = train_data
y = train_labels
for i in range(len(X)):
for j in range(len(X.columns)):
try:
int(X[j][i])
except:
print(i)
break
577
|
| In [76]: |
#Bozuk veriler içeren satır veri kümesinden temizlenir.
X.drop([577], axis=0, inplace=True)
X1 = X.reset_index(drop=True)
y.drop([577], axis=0, inplace=True)
y1 = y.reset_index(drop=True)
Veri kümesinde çok fazla sayıda öznitelik mevcut. Bu özniteliklerin sonuca götüren yolda ne kadar önemli olduğunu görmek için feature selection işlemi uygulayacağız ve en önemli 50 özniteliği gözlemleyeceğiz. Bu öznitelikler içerisinden de önem skorlarına göre en optimum seçimleri gerçekleştirip modeli bu öznitelikler üzerinden eğiteceğiz.
|
| In [77]: |
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
BestFeatures = SelectKBest(score_func=chi2, k=10)
fit = BestFeatures.fit(X1,y1)
df_scores = pd.DataFrame(fit.scores_)
df_columns = pd.DataFrame(X1.columns)
f_Scores = pd.concat([df_columns,df_scores],axis=1)
f_Scores.columns = ['Specs','Score']
k = f_Scores.nlargest(50,'Score').reset_index(drop=True)
k
|
| Out [77]: |
| |
Specs |
Score |
| 0 |
475 |
1122.310709 |
| 1 |
105 |
1115.426580 |
| 2 |
336 |
1013.553732 |
| 3 |
64 |
711.303432 |
| 4 |
493 |
568.016647 |
| 5 |
338 |
553.943167 |
| 6 |
241 |
537.545785 |
| 7 |
442 |
496.842316 |
| 8 |
453 |
470.716457 |
| 9 |
378 |
176.168849 |
| 10 |
48 |
105.185928 |
| 11 |
472 |
93.958452 |
| 12 |
153 |
37.816738 |
| 13 |
411 |
22.103693 |
| 14 |
136 |
18.540337 |
| 15 |
329 |
16.513402 |
| 16 |
433 |
15.172222 |
| 17 |
347 |
15.157097 |
| 18 |
204 |
14.890550 |
| 19 |
494 |
13.205522 |
| 20 |
211 |
13.122936 |
| 21 |
56 |
12.725947 |
| 22 |
10 |
12.686245 |
| 23 |
4 |
12.163263 |
| 24 |
149 |
11.608932 |
| 25 |
281 |
11.145225 |
| 26 |
431 |
9.988660 |
| 27 |
286 |
9.206459 |
| 28 |
458 |
9.111032 |
| 29 |
128 |
8.620484 |
| 30 |
199 |
8.612353 |
| 31 |
46 |
8.579297 |
| 32 |
175 |
7.904475 |
| 33 |
296 |
7.628948 |
| 34 |
221 |
7.558888 |
| 35 |
73 |
6.859966 |
| 36 |
246 |
6.818070 |
| 37 |
85 |
6.789738 |
| 38 |
457 |
6.303273 |
| 39 |
119 |
6.224970 |
| 40 |
24 |
6.193625 |
| 41 |
333 |
6.137223 |
| 42 |
245 |
6.094586 |
| 43 |
285 |
6.039487 |
| 44 |
164 |
5.845417 |
| 45 |
298 |
5.510903 |
| 46 |
41 |
5.498647 |
| 47 |
414 |
5.474831 |
| 48 |
382 |
5.348231 |
| 49 |
430 |
5.193953 |
Sonuçlar neticesinde diğerlerine oranla çok daha önemli gördüğümüz ilk 12 öznitelik ile modelimizi oluşturmaya devam edeceğiz. Bu aşamada belirlediğimiz 12 öznitelik ile yeni bir veri kümesi oluşturup farklı bir değişkene atıyoruz. |
| In [78]: |
l = k.loc[:11,:]
list_ = list(l["Specs"])
X2 = X1.loc[:, list_]
y2 = y1[0]
X2.head()
|
| Out [78]: |
| |
475 |
105 |
336 |
64 |
493 |
338 |
241 |
442 |
453 |
378 |
48 |
472 |
| 0 |
401 |
181 |
658 |
648 |
485 |
628 |
434 |
568 |
471 |
419 |
440 |
515 |
| 1 |
549 |
431 |
469 |
488 |
338 |
528 |
551 |
463 |
311 |
526 |
499 |
465 |
| 2 |
454 |
593 |
465 |
485 |
650 |
431 |
474 |
503 |
606 |
464 |
460 |
485 |
| 3 |
602 |
698 |
398 |
415 |
572 |
377 |
569 |
447 |
545 |
553 |
529 |
457 |
| 4 |
560 |
451 |
385 |
387 |
435 |
509 |
538 |
536 |
426 |
424 |
429 |
500 |
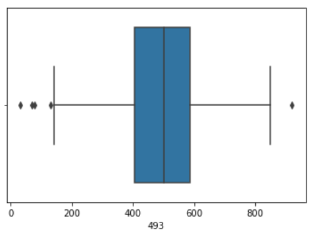
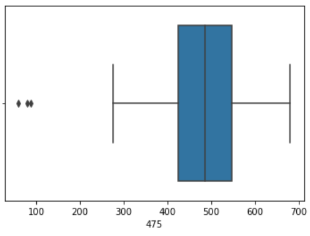
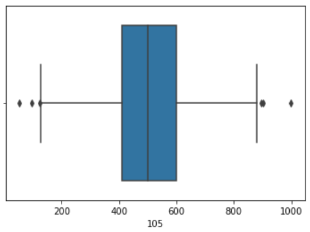
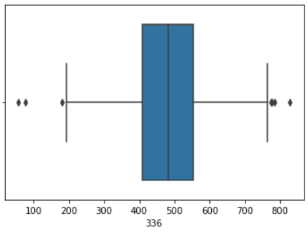
Veri önişleme adımını tamamlamadan önce her bir özniteliğe ait değerler kümesinde aykırı değerler olup olmadığını boxplot çizdirerek net bir biçimde gözlemliyoruz. Aykırı değerleri tespit edip bunları ortalama değerler ile değiştireceğiz.
|
| In [79]: |
import seaborn as sns
for v in list_:
X2[v] = X2[v].astype(int)
sns.boxplot(x = X2[493])
|
| Out [79]: |
<AxesSubplot:xlabel='493'>
|
| In [80]: |
sns.boxplot(x = X2[475])
|
| Out [80]: |
<AxesSubplot:xlabel='475'>
|
| In [81]: |
sns.boxplot(x = X2[105])
|
| Out [81]: |
<AxesSubplot:xlabel='105'>
|
| In [82]: |
sns.boxplot(x = X2[336])
|
| Out [82]: |
<AxesSubplot:xlabel='336'>
|
| In [83]: |
sns.boxplot(x = X2[64])
|
| Out [83]: |
<AxesSubplot:xlabel='64'>
|
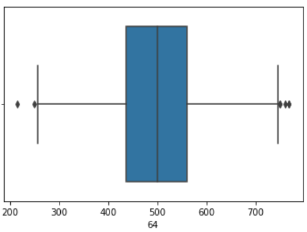
| In [84]: |
#Tüm öznitelikler için aykırı değerleri ortalama değerler ile değiştiriyoruz.
for value in list_:
df_table = X2[value].copy()
Q1 = df_table.quantile(0.25)
Q3 = df_table.quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5*IQR
upper_bound = Q3 - 1.5*IQR
outliers_vector = (df_table < (lower_bound)) | (df_table > (upper_bound))
outliers = df_table[outliers_vector]
df_table[outliers_vector] = df_table.mean()
X2[value] = df_table
|
| In [85]: |
#Aykırı değerlerin ortalama değerler ile değiştirilip değiştirilmediğini kontrol ediyoruz.
sns.boxplot(x = X2[64])
|
| Out [85]: |
<AxesSubplot:xlabel='64'>
|
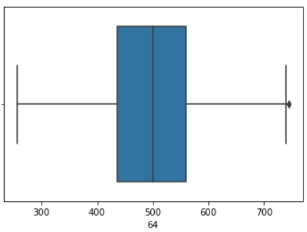
| In [86]: |
sns.boxplot(x = X2[336])
|
| Out [86]: |
<AxesSubplot:xlabel='336'>
|
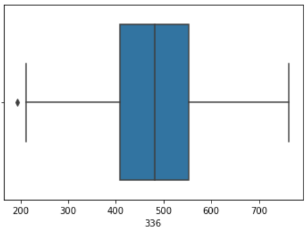
| In [87]: |
sns.boxplot(x = X2[493])
|
| Out [87]: |
<AxesSubplot:xlabel='493'>
|
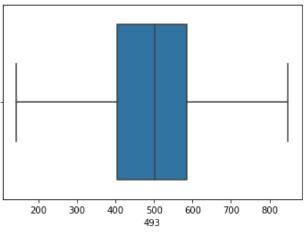
Tüm veri önişleme adımlarını tamamladık, artık veri kümesi eğitilmeye ve tahmin yapmaya hazır durumda. Bu adımda seçtiğimiz sınıflandırma algoritmaları (DecisionTree, RandomForest, Support Vector Machine) ile öğrenme ve tahmin etme işlemlerini gerçekleştireceğiz. Bu algoritmaları tercih etmemizin sebebi bu alanda en çok tercih edilen ve başarılı çıktılar üreten algoritmalar olmalarıdır.
| In [88]: |
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(X2, y2)
test = valid_data.loc[:, list_]
for v in list_:
test[v] = test[v].astype(int)
predictions_dt = clf.predict(test)
from sklearn.ensemble import RandomForestClassifier
clf=RandomForestClassifier()
clf.fit(X2, y2)
predictions_rf = clf.predict(test)
from sklearn.svm import SVC
clf = SVC()
clf.fit(X2, y2)
predictions_svm = clf.predict(test)
|
| In [89]: |
#Elde ettiğimiz tahminleri gerçek etiketler ile karşılaştırarak modellerimizin başarı oranlarını kıyaslayabiliriz.
from sklearn import metrics
from sklearn.metrics import confusion_matrix
print("Accuracy_RF:",metrics.accuracy_score(label, predictions_rf))
print("Accuracy_DT:",metrics.accuracy_score(label, predictions_dt))
print("Accuracy_SVM:",metrics.accuracy_score(label, predictions_svm))
print("--------------------------------")
print("F1_RF:",metrics.f1_score(label, predictions_rf))
print("F1_DT:",metrics.f1_score(label, predictions_dt))
print("F1_SVM:",metrics.f1_score(label, predictions_svm))
print("--------------------------------")
print("Precision_RF:",metrics.precision_score(label, predictions_rf))
print("Precision_DT:",metrics.precision_score(label, predictions_dt))
print("Preciison_SVM:",metrics.precision_score(label, predictions_svm))
print("--------------------------------")
print("Recall_RF:",metrics.recall_score(label, predictions_rf))
print("Recall_DT:",metrics.recall_score(label, predictions_dt))
print("Recall_SVM:",metrics.recall_score(label, predictions_svm))
Accuracy_RF: 0.88
Accuracy_DT: 0.785
Accuracy_SVM: 0.8333333333333334
--------------------------------
F1_RF: 0.8791946308724832
F1_DT: 0.7902439024390244
F1_SVM: 0.8310810810810811
--------------------------------
Precision_RF: 0.8851351351351351
Precision_DT: 0.7714285714285715
Preciison_SVM: 0.8424657534246576
|
| In [90]: |
confusion_matrix(label, predictions_rf)
|
| Out [90]: |
array([[266, 34],
[38, 262]], dtype=int64)
|
| In [91]: |
confusion_matrix(label, predictions_dt)
|
| Out [91]: |
array([[228, 72],
[57, 243]], dtype=int64)
|
| In [92]: |
confusion_matrix(label, predictions_svm)
|
| Out [92]: |
array([[254, 46],
[54, 246]], dtype=int64)
|
Seçtiğimiz 3 algoritma için de birer model oluşturarak tahminleri gerçekleştirdik. Tahminler gerçek değerler ile karşılaştırıldı ve değerlendirebilmek için confusion matris çıktıları alındı. Modelin başarılı bir model olması için Precision, F1 Measure, Recall, Accuracy gibi değerlerin mümkün olduğunca yüksek çıkmasını bekliyoruz. Buradaki sonuçlar dikkate alındığında en başarılı modelin Random Forest algoritması ile oluşturulduğu gözlemlenmiştir. Başarı oranı sıralamasında Random Forest algıritmasını Support Vector Machine algoritması takip etmektedir.


Güzel ve detaylı bir inceleme olmuş, elinize sağlık.