Yapay Zeka Modellerine Yönelik Tehditler
Large Language Model (LLM) ile çağ atlayan, bilişim ile uğraşan veya uğraşmayan herkes tarafından kullanılabilir hale gelen yapay zekâ bu kadar yaygınlaşmışken biraz da konuya farklı bir pencereden bakalım istedim. Bir yapay zekâ modeli her zaman güvenilir midir? Modele dışarıdan etki ederek yanlış çıktılar üretmesi sağlanabilir mi? Yapay zekâ kullanımı atak yüzey alanımızı genişletir mi? ...

05.12.2024

Large Language Model (LLM) ile çağ atlayan, bilişim ile uğraşan veya uğraşmayan herkes tarafından kullanılabilir hale gelen yapay zekâ bu kadar yaygınlaşmışken biraz da konuya farklı bir pencereden bakalım istedim.
Bir yapay zekâ modeli her zaman güvenilir midir? Modele dışarıdan etki ederek yanlış çıktılar üretmesi sağlanabilir mi? Yapay zekâ kullanımı atak yüzey alanımızı genişletir mi?
Birçoğumuzun aklına bu tarz soruların bu yazıyı okuyana kadar gelmediğini biliyorum. Fakat bu soruların ilki 2004 yılında John Graham-Cumming’in aklına gelmişti:
“Makine öğrenmesi ile spam e-mail tespiti yapan bir modeli nasıl yanıltabilirim?”[1]
İşte konumuzun ilk ortaya çıkışı bu MIT spam konferansına dayanıyor. Takip eden yıllarda çok fazla çalışma yapılmamış olsa da derin öğrenme modellerinin kullanımının yaygınlaşmasıyla birlikte yapay zekâ güvenliği konusu ivme kazandı. 2015 yılında Google mühendisleri Goodfellow ve arkadaşları tarafından yayımlanan “Explaining and Harnessing Adversarial Examples”[2] başlıklı çalışma bu alanda yeni bir boyut açmıştır. Aşağıda yer alan çalışmadaki görsel yapay zekâ güvenliği denilince hâlâ ilk akla gelen görsellerden biridir. Biz de konuyu bu görsel üzerinden özetleyelim.
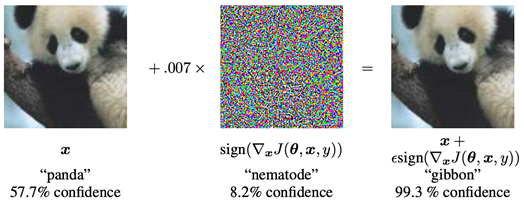
Soldaki görselde bir panda var ve model bu görseli %57.7 kesinlik ile "panda" olarak sınıflandırmış. Ortadaki görüntü, girdiye eklenen bir gürültü (pertürbasyon) ve bu gürültü "nematode" (bir tür solucan) olarak %8.2 kesinlik ile sınıflandırılmış. Sağdaki görsel ise, orijinal panda görseline küçük gürültünün eklenmiş hali ve model bu yeni görüntüyü %99.3 güvenle "gibbon" (bir tür maymun) olarak sınıflandırmış. Bu örnek, makine öğrenimi modellerinin küçük ama kasıtlı değişikliklere nasıl kolayca yanıt verip yanlış sınıflandırma yapabildiğini gösteriyor. İnsan gözü için orijinal ve değiştirilen görseller arasındaki fark çok küçük olsa da model bu değişikliği büyük olarak algılayarak tamamen yanlış bir sınıflandırma yapıyor. Bu en temel örnek basit ve zararsız olarak görülebilir fakat bu modellerin otomotiv, sağlık, güvenlik gibi alanlarda kullanıldığını ve bu atakların o sektörlerde uygulandığı senaryolarını düşündüğümüzde işin korkutucu boyuta ulaşabileceği görülebilir.
Yapay zekâ modellerine yönelik ataklar elbette ki sadece görsel sınıflandırma modelleriyle sınırlı değil. Sesten metin üreten modellere yönelik ataklar[3], saldırı tespit sistemlerine (IDS) yönelik ataklar[4] ve son zamanlarda özellikle popüler hale gelen doğal dil işleme modellerine yönelik ataklar[5] da gerçeklenmektedir. Zaman içerisinde bu atakların gerçeklenmesini kolaylaştıran ve aynı zamanda savunma senaryoları da gerçekleyen bazı open source tool’lar da geliştirilmiştir. Bunlara Adversarial Robustness Toolbox (ART), Foolbox ve Torchattacks örnek olarak verilebilir.
Yapay zekâ modellerine yönelik saldırılar birkaç farklı kritere göre gruplandırılabilir:
1. Saldırı Bilgi Seviyesine Göre:
- White-Box (Beyaz Kutu) Saldırılar:
o Saldırganın, modelin iç yapısını, ağırlıklarını, aktivasyon fonksiyonlarını ve diğer tüm detaylarını bildiği senaryodur
o Saldırgan, bu bilgileri kullanarak girdiyi modelin sınıflandırma doğruluğunu azaltacak şekilde değiştirir.
Örnek: Fast Gradient Sign Method (FGSM), Projected Gradient Descent (PGD).
- Black-Box (Kara Kutu) Saldırılar:
o Saldırganın model hakkında hiçbir bilgiye sahip olmadığı senaryodur. Yalnızca giriş ve çıkışları kullanarak saldırı gerçekleştirir.
o Saldırganlar, modelin tahminlerine dayanarak girişleri değiştirir.
Örnek: Zeroth-Order Optimization (ZOO), Query-Based Attacks.
- Gray-Box (Gri Kutu) Saldırılar:
o Saldırgan modelin bazı bilgilerine erişebilir (Örneğin, mimariyi biliyor ancak ağırlıkları bilmiyor). Bu bilgilerle saldırıyı gerçekleştirmeye çalışır.
2. Hedefliliğe Göre:
- Targeted (Hedefli) Saldırılar:
o Saldırgan, modelin girdi örneğini belirli bir sınıfa yanlış sınıflandırmasını sağlamaya çalışır.
Örnek: Bir pandanın fotoğrafını modele "kedi" olarak yanlış sınıflandırılması için değiştirir.
- Untargeted (Hedefsiz) Saldırılar:
o Saldırganın amacı, modelin doğru sınıflandırmayı yapmasını engellemektir, ancak hangi sınıfa yanlış sınıflandırdığı önemli değildir.
Örnek: Bir pandayı, yanlış sınıf olarak sınıflandıracak şekilde modelin yanıtını değiştirmek.
3. Saldırı Yönüne Göre:
- Evasion (Kaçınma) Saldırıları:
o Eğitim tamamlandıktan sonra test aşamasında uygulanan saldırılardır.
o Modelin doğru sınıflandırma yapmasını önlemeyi amaçlar.
Örnek: Görüntü işleme modellerinde minik gürültüler ekleyerek görüntüyü yanlış sınıflandırma.
- Poisoning (Zehirleme) Saldırıları:
o Eğitim aşamasında gerçekleştirilen saldırılar.
o Veriye kasıtlı olarak yanlış örnekler eklenerek modelin yanlış öğrenmesi sağlanır.
Örnek: Sahte veya zararlı verilerle eğitim setini bozmak.
- Extraction Saldırıları:
o Saldırganın bir makine öğrenimi modelinin parametrelerini, öğrenme ağırlıklarını dışarıdan gözlemleyerek veya test ederek çıkarmaya çalıştığı bir saldırı türüdür. Saldırgan, sınırlı sayıda sorgu ile modelin nasıl çalıştığını anlamaya çalışır.
Örnek: Bir saldırgan, bir API'ye birden fazla sorgu gönderir ve modelin verdiği cevaplardan yola çıkarak, modelin iç yapısı ve parametreleri hakkında bilgi elde eder.
- Inversion Saldırıları:
o Modelin çıktısına bakarak orijinal girdiyi veya girdi ile ilgili bilgileri geri kazanmayı hedefler. Bu saldırı, özellikle gizlilik ihlallerine neden olabilir. Saldırgan, modelin çıktısından orijinal veriyi veya hassas bilgileri yeniden oluşturmaya çalışır. Bu, verilerin gizliliğini tehlikeye atar.
Örnek: Bir yüz tanıma modeli, bir kişinin yüzünü tanıttığında, saldırgan modelin verdiği çıktılardan o kişinin yüzünü geri elde etmeye çalışır. Böylece modelin girdisi geri kazanılabilir.
Yapay zekâya yönelik tehditlerden ve atak türlerinden bahsettik. Peki bu ataklar nasıl gerçeklenebilir? Burada devreye farklı senaryolarda kullanılabilecek farklı metotlar girmektedir. İşte bu metotlardan bazıları şunlardır:
1. Fast Gradient Sign Method (FGSM):
- Bu saldırı, modelin kayıp fonksiyonuna göre girişin gradyanını kullanarak girişe küçük bir gürültü ekler. Modelin sınıflandırma performansını bozmak için hızlı ve etkili bir yöntemdir.
- Beyaz kutu (white-box) saldırılarında tercih edilir, hızlıdır ve minimum gürültü ekleyerek modelin tahminini değiştirir.
2. Projected Gradient Descent (PGD):
- FGSM'nin çok adımlı versiyonudur. Girişin sınırlı bir alanda kalmasını sağlarken iteratif olarak gürültü ekler ve daha güçlü bir saldırı üretir.
- Beyaz kutu saldırılarında tercih edilir ve genellikle en güçlü saldırılardan biri olarak kabul edilir.
3. Carlini & Wagner (C&W) Saldırısı:
- Bu saldırı, hedefli bir saldırı olarak geliştirilmiştir ve girdilere yapılan küçük değişikliklerle modeli belirli bir sınıfa yanlış sınıflandırmaya zorlar. Modelin güvenini maksimize ederek yanlış tahminler yapmasını sağlar.
- Beyaz kutu saldırılarında tercih edilir, çok güçlüdür ve birçok savunma stratejisine karşı etkili olabilir.
4. Zeroth-Order Optimization (ZOO) Saldırısı:
- Kara kutu (black-box) saldırılarında kullanılır. Modelin çıktısına dayanarak girişleri optimize eder ve saldırı yapar. Modelin iç yapısını bilmeden, yalnızca tahminler kullanılarak saldırı gerçekleştirilir.
- Kara kutu saldırı, model hakkında bilgiye ihtiyaç duymaz ve bu yönüyle geniş bir kullanım alanına sahiptir.
REFERANSLAR
1. John, GRAHAM-CUMMING. "How to Beat a Bayesian Spam Filter." http://www. spamconference. org (2004).
2. Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. "Explaining and harnessing adversarial examples." arXiv preprint arXiv:1412.6572 (2014).
3. https://nicholas.carlini.com/code/audio_adversarial_examples
4. S. Alper, “A robust machine learning based IDS design against adversarial attacks in SDN,” Ph.D. - Doctoral Program, Middle East Technical University, 2024.
Bu kapsamlı incelemeniz oldukça bilgilendiriciydi. Özellikle adversarial saldırı türleri ve etkileri üzerine sunduğunuz örnekler, farkındalık geliştirmeme katkı sağladı. Bu tehditlere karşı eğitimli savunma sistemlerinin nasıl bir çözüm sunabileceği ve daha dirençli modeller geliştirmek için hangi etik ve teknik önlemlerin öncelikli olması gerektiği konusundaki görüşlerinizi merak ediyorum.